The data analysis profession has evolved and gone through various stages of success. In a modern enterprise, business data is collected from various applications and tools of different functions. The resulting data sets have become so massive and complex that there is a need for a new function to bridge the gap between raw data and data that can be used to drive business decisions — the BI Engineer.
Evolution of the BI Engineer
To understand the role of a BI Engineer, we must first understand the distinction between raw data and analytical data.
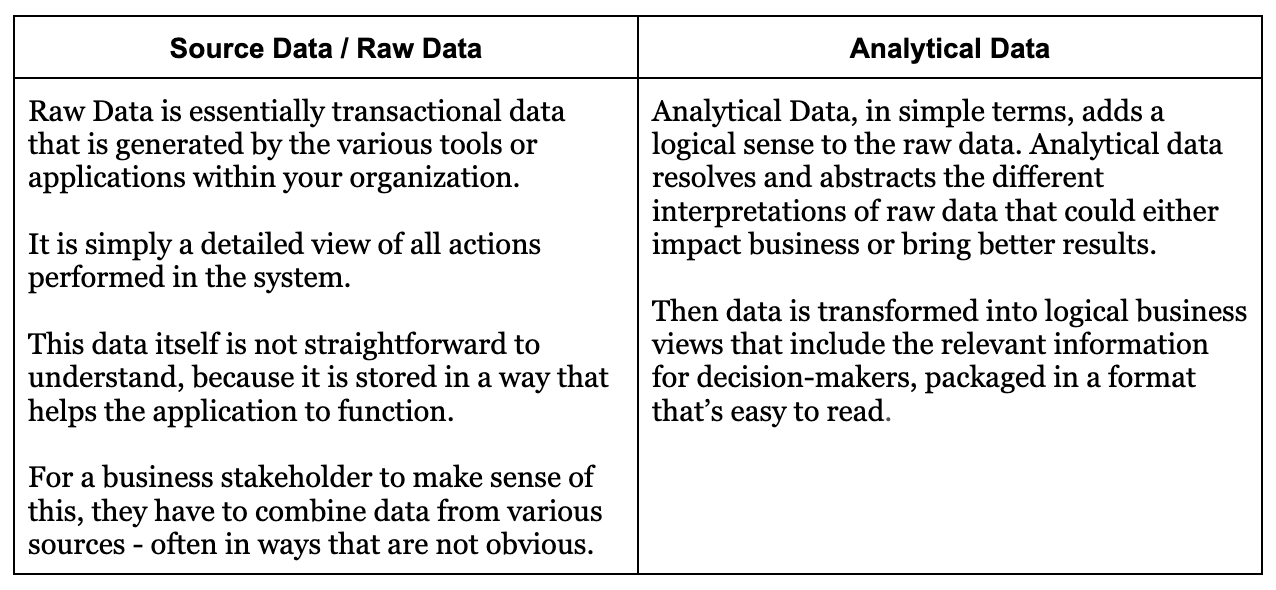
When organizations first started using data, data analysts would work with raw data to find answers to specific questions related to various business processes at a micro-level. At this stage, data was used to improve micro-level efficiencies but did not yet play a significant role in regular strategic reporting or planning. To bridge this gap, data analysts began figuring out ways to build analytical representations of data that would be easy for business functions to consume.
What does a BI engineer do?
A BI engineer is responsible for building reports and tools with the objective of improving the integration of data with business processes and planning.
Moreover, a BI Engineer should push to build these solutions while ensuring that the data is always correct, complete and accurate.
How is this different from Data Analysis or Platform Engineering?
BI Engineers sit at the intersection of business teams, analytics and data engineering. They bring a formal and rigorous software engineering practice to the efforts of analysts and data scientists, and they bring an analytical and business-outcomes mindset to the efforts of data engineering. In brief, these are the different players and the role they play in a data organization:
Data Platform Engineer: Manages core data infrastructure, ensuring data is available and accessible across the organization.
Data Analyst: Partners with business stakeholders to draw meaningful business insights from data.
Data Science: Use statistics & machine learning to discover patterns and respond to complex questions where relationships between the various entities are not clearly understood.
BI Engineer: Converts raw data into meaningful data models so that analysts can directly use it to draw insights. May also be responsible for connecting these insights with business tools, processes or practices — in ways that are automated and reliable.
How do you set up a BI Engineering Stack?
While setting up a BI Engineering stack, it helps to take stock of your objectives. In our cases, we decided to divide these into business and technical objectives:
Business Objectives
- Transform raw data into meaningful models
- Ensure a Single Source of Truth for all business KPIs
- Make data easy to discover and understand
- Keep track of lineages to allow deep dives of metrics
Technical Objectives
- Modularise transformation scripts for ease of maintenance and reusability
- Improve data reliability and Minimise data downtimes
- Maintain history of changes
- Make pipelines easier to repair in case of failure
What does a modern BI Toolchain look like?
To answer this question, we’ll break down the flow of data in the BI toolchain to its various stages, present the tools we use at grofers as well as some good alternatives.
- Replication
- Orchestration
- Transformation / Data Definition
- Storage & Access
Replication
Replication (or extraction) is arguably the first step in any data pipeline. At Grofers we need to transport a substantial volume of data from our source databases to our data lake every day. Because of the size of this data, any third-party tool would have cost us a fortune — so we built our own “Source Replication System” based on Change Data Capture powered by Debezium.
While we’ve relied heavily on tools like Xplenty in the past to allow data analysts to program their own pipelines, we’ve found that they don’t handle very well at scale. We found it easier and better to replace these with scheduled scripts.
If you’re looking for simpler alternatives to set up your own replication systems, Fivetran is a good alternative. If you prefer to use open-source tools, you have Airbyte.
Orchestration
For orchestration of our pipelines, we rely exclusively on Airflow. Airflow is an amazing tool, and we intend to write a complete article on some of the features that we love in particular. Our data platforms team has also built a very cool tool that allows us to schedule Jupyter Notebook runs via Airflow, and all it takes is a simple config file.
While we prefer to host our instance of Airflow ourselves, if you’re just starting out with your data operations and don’t want all the overhead of maintaining all your services, you can use services like Astronomer, Google Cloud Composer or Amazon MWAA.
Airflow is so full of cool features that we will follow up with a dedicated article expounding upon the parts of Airflow that we like the most.
Transformation / Data Definition
DBT (Data Build Tool) is an open-source data transformation tool that enables data analysts and engineers to transform, test and document data in the cloud data warehouse. DBT is arguably one of the most transformative tools to come up within the data ecosystem in recent years.
DBT essentially allows you to apply programming practices that are otherwise unavailable in SQL — variables, modular pipelines, cross-referencing and in-built testing. We’ve only started to implement DBT recently, but we’re completely in love with how understandable it makes your SQL scripts.
Storage & Access
Historically, Redshift was the only data warehouse used at Grofers, and it still continues to support the major bulk of our use cases. However, given the large volumes of raw data we generate, we have recently started migrating to an Apache HUDI data lake stored on S3, that we query through a Presto Engine. If you prefer to use a managed service, Google BigQuery or Snowflake are other alternatives that allow you to decouple your storage and compute. This market space has also seen some new entrants like Firebolt, who make exciting claims about their query processing capabilities — but we haven’t been able to test these yet.
Conclusion
Analytics or BI Engineering is a relatively new role that has come up in the data ecosystem, born out of the need to bridge the gap between data engineering and business intelligence. A BI Engineer is responsible for ensuring you have the right data available when you need it, where you need it and in a form that’s easy to use.
By making data easier to use, having a BI Engineering team in your organization enables more business functions to access relevant data without expert intervention — thereby moving you further on the path to being data-driven.
As the BI Engineering team at grofers, we’ve been working hard to drive data adoption and make sure that all the KPIs add up, across the organization. Over the next few articles, we’re going to share more about the tools that help us build well-designed data models that are easy to maintain and with 0 downtimes.





