Journey of Zero Downtime Migration of Elasticsearch at Blinkit
Blinkit is pivoting towards the quick commerce area, where it aims to provide its customers with a smooth shopping experience. Customers should be able to find and search for what they are looking for. We manage such product catalogs in Elasticsearch because it provides custom search capabilities across massive catalogs at the merchant level. As we moved to a quick commerce platform, we needed to migrate the old Elasticsearch cluster to a newer one. This migration will enable us to handle heavy read & write requests and to utilize new inbuilt features of Elasticsearch by eliminating tech debts and hacks from our search and discovery systems.
We had been using the Elasticsearch 2.4 cluster in the production environment since 2012 when Blinkit was found (formerly grofers) to power up search and catalog on our app. The overall infrastructure generated huge maintenance costs per month and required immense knowledge to maintain the self-managed cluster in production. As time passed, the Elasticsearch community released various new features which were not supported by Elasticsearch 2.4, like a shorter way of writing Elasticsearch queries, typeless API, better data management, data modeling and visualization using Kibana.
After carefully comparing both the Elasticsearch versions, we decided to migrate our Elasticsearch cluster to the newer version, 7.5.
Benefits of New Elasticsearch 7.5
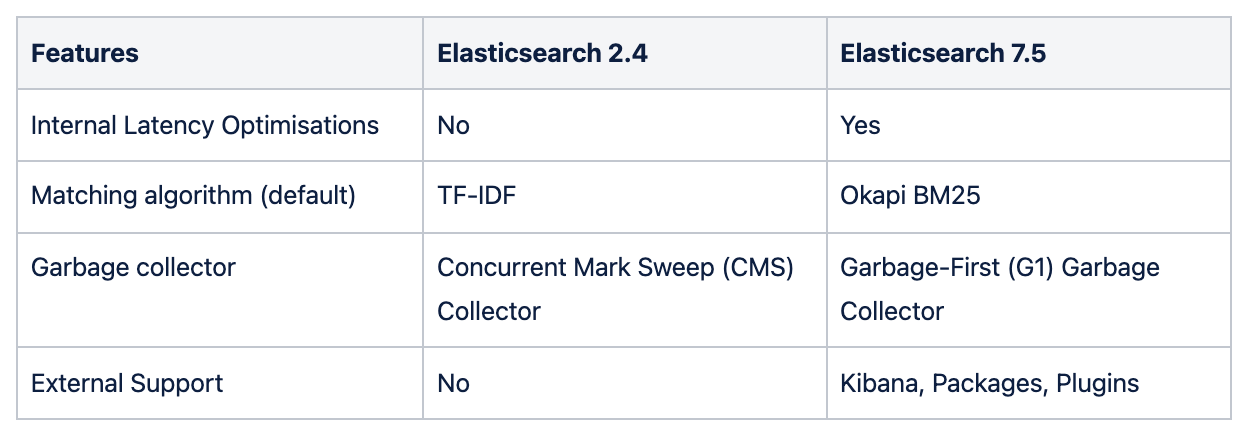
Elasticsearch 7.5 provides many benefits like internal latency optimizations, changes in matching and similarity algorithm, garbage collector, external plugins, and package support.
Features comparison between old and new Elasticsearch versions
Ranking models can also be imported and supported by the new Elasticsearch. For example, The Learning To Rank (LTR) plugin can be used to improve search relevance ranking.
The Business Usecase
Since we’re moving to a quick commerce platform with a 10 mins delivery model, the number of merchants will scale up 10x. To put into perspective, there will be thousands of products per merchant, which will generate a catalog in the millions. Apart from maintaining a vast product catalog at each merchant level, our search rate will increase dramatically. Our daily searches contribute to around 36k requests/min. Scale-up would result in more than 200k requests/min daily searches at such a level. Our Elasticsearch should be efficient in handling such requests and maintaining the catalog without any lag at the customer experience end. The old cluster couldn’t provide us with the performance that we now require in terms of indexing huge amounts of data both in terms of time and querying. The migration would help us improve the Elasticsearch node performance, CPU usage, disk usage and query time performance.
Self-managed Vs. AWS managed cluster
We were using Elasticsearch 2.4 as a self-managed cluster. The nodes on the self-managed cluster were hosted on AWS EC2 instances. The self-managed clusters provide many options to upgrade on different EC2 instances based on usability. However, we were running X nodes on large EC2 instances which were generating high infra cost per month. The self-managed cluster also had other limitations like domain expertise–it takes time to get familiar with any new software. This also involves high-time investment in learning and managing the production cluster. Managing such a cluster also requires additional management work in infrastructure setup.
We decided to go ahead with AWS-managed cluster i.e. AWS Opensearch Service with version 7.5:
It is easy to set up, and it takes care of everything like setup, configuration and maintenance.
It also provides cross A-Z availability backup options of clusters for failure recovery.
It supports external services like Kibana.
Upscaling and downscaling of nodes takes around 5–10 minutes and can be performed through the AWS Opensearch service dashboard. Vertical scaling of the cluster happens by blue-green deployment without affecting the production.
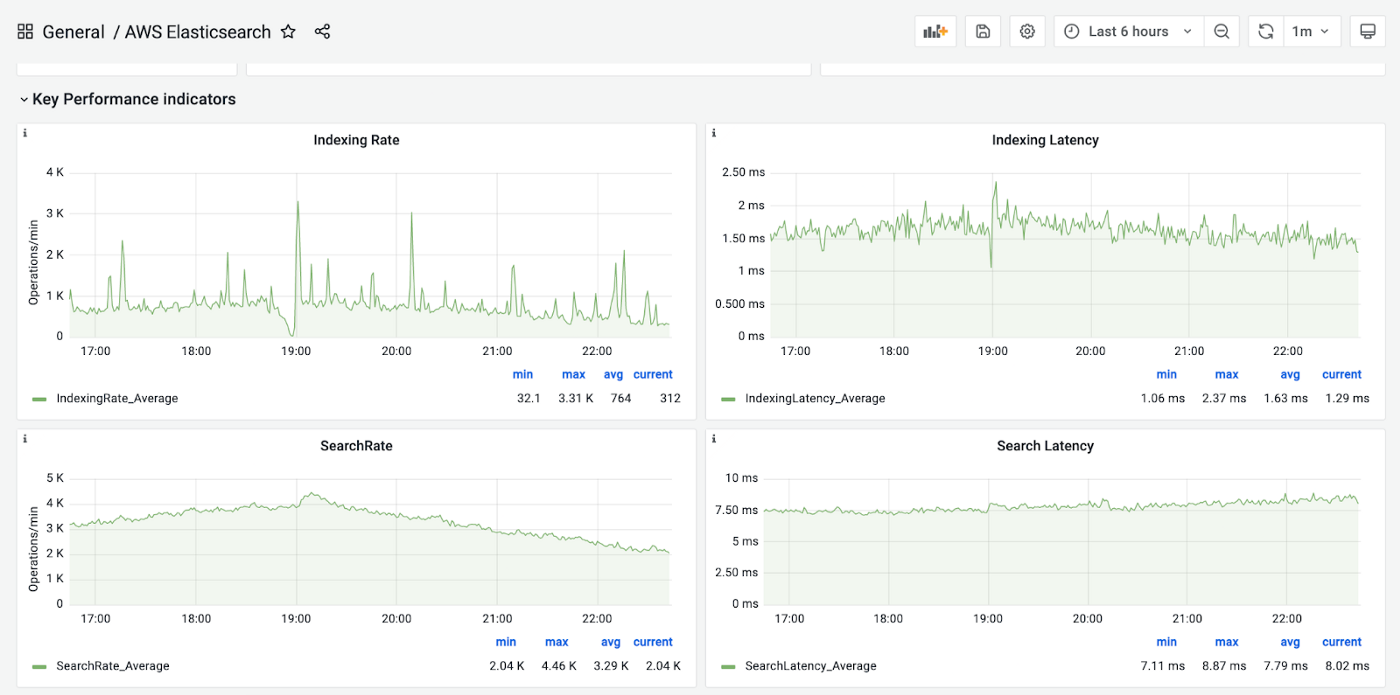
AWS Opensearch service also provided us with monitoring metrics of search rate, search latency, indexing rate, indexing latency, data node CPU and memory utilization and master node CPU and memory utilization.
However, such clusters also have a few limitations like — it is heavily limited in terms of the cluster configuration. There is no support for Auto Scaling Groups (ASGs), and manual intervention is required to scale up the cluster. There are additional costs associated with the cluster.
But in our case — we found it much better and cheaper than maintaining nodes on EC2 instances. If something goes wrong with the cluster — it’s difficult to manually restart the cluster since AWS provides limited Elasticsearch APIs to interact with the cluster. In such a case, asking for help from AWS support is only the last step, which takes around 30–60 minutes to bring the cluster back into operational state.
The Action plan
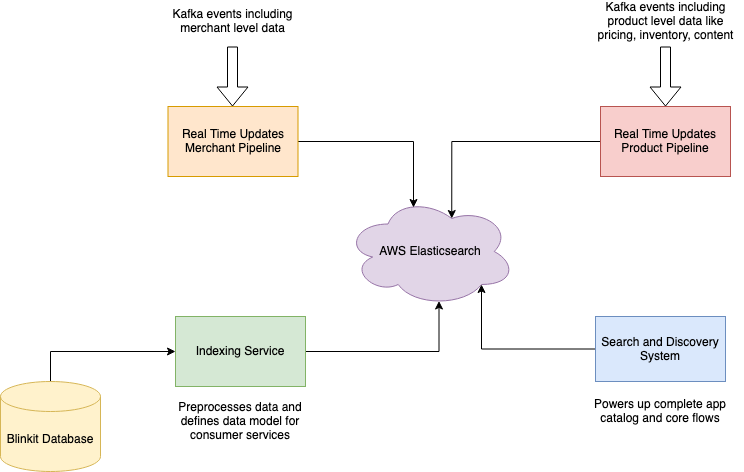
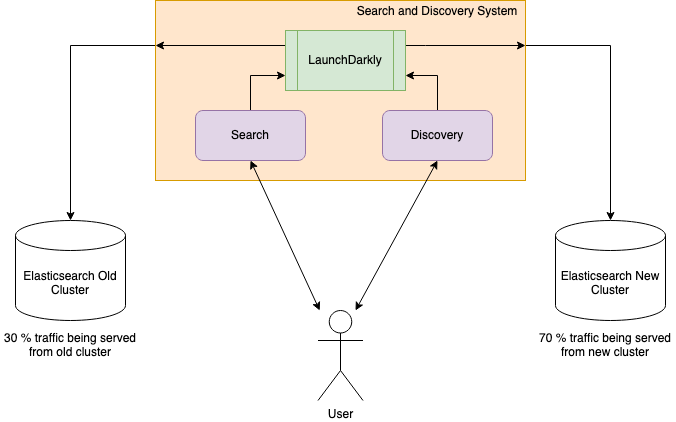
We created an action plan to migrate our Elasticsearch to a newer version. We decided to shift from a self-managed cluster to an AWS-managed cluster. The planning took time, as it required us to identify the changes that would break across consumer services while handling deployments with zero downtime. We used around five consumer services (including a monolith legacy service written in 2015, i.e., six years old and handling approx. 1M requests/min), dependent on Elasticsearch. Such services were responsible for driving core flows of the Blinkit app like product listing page (PLP), product display page (PDP), search results, search suggestions, real-time incremental update pipeline, and product recommendations, as shown in the figure below.
Consumer Indexing Architecture
It also included an immense work plan for handling and setting up the new infrastructure with the old one by running two production clusters of Elasticsearch in parallel and had other challenges like keeping data in sync across both clusters. To accommodate such changes, it also required maintaining dual-code changes, one with new replicated functions and the other one with old functions. Our responsibility was to clean up the replicated code once the migration was complete and 100% of the requests were served from the new Elasticsearch cluster.
Challenges while migrating
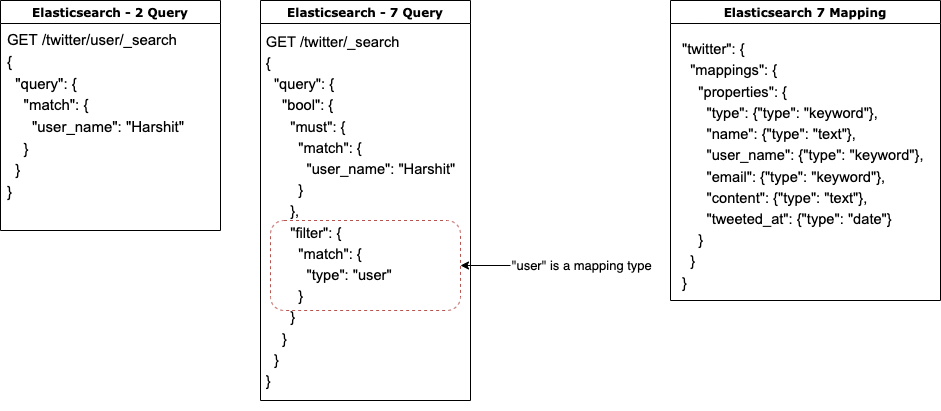
One of the significant ES migration challenges was refactoring the mappings structure w.r.t new Elasticsearch version without breaking production. This required a lot of study around Elasticsearch and how it handles mappings. In Elasticsearch 2.4, an index was capable of storing mappings as “mapping type.” Querying data is also different as it happens on the mapping type level.
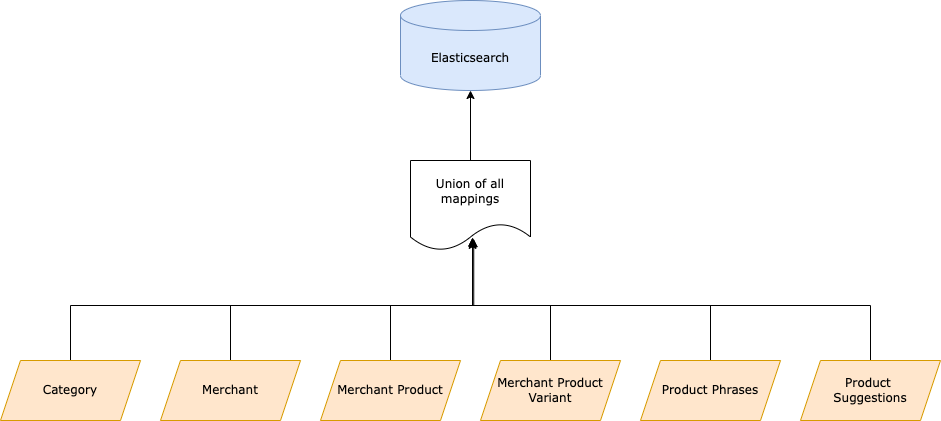
From Elasticsearch 7.5 onwards, they introduced a new feature called Typeless API. They have deprecated the mapping type feature. They suggest that if we have seven mappings types, there should be seven different indexes. However, this was a big challenge for us to handle different mappings at different indexes. Instead of going with the suggested solution, we maintained the mapping structure by taking a union of all mapping types as a single entity with aggregated fields representing a complete mapping and adding a new custom field by the name “mapping_type” to distinguish among the different document schemas. Typeless API means that you can query the document without mentioning its type. For example, consider an index at Elasticsearch 2.4 cluster. It will have — an index name, mapping type and search API.
A comparison between the two
Here, “user” is a mapping type.
At a document level, a custom field name has been defined by name “type” which indirectly tells us about mapping type. In this way, typeless API can be used to query the data.
Defining different mapping types at single index level
After aggregating all the mapping types, we also had to deal with key duplication. However, after defining a custom field named “mapping_type,” ES treated those keys as unique keys at each “mapping_type” level. In this way, we saved ourselves against key duplication. This was the second challenge — key duplication which subsequently resolved itself. It was essential to solve such scenarios to avoid erroneous data querying from our consumer services.
Production deployment across consumer services
We had few production constraints when it came to the deployment of the new Elasticsearch cluster. The first constraint was — zero downtime migration. We have active users on our platform, and we cannot afford the system to be down during migration. The second constraint was — recovery plan. We cannot afford to lose or corrupt the data at any cost. So, we needed to be prepared with a recovery plan if the migration failed. The third constraint was zero bugs in the system. It was our responsibility to avoid changing existing functionalities for end-users.
For the production deployment of Elasticsearch migration-related changes we had two options:
Follow canary-based deployment.
Follow blue-green-based deployment.
In our case, canary-based deployment suited better. Blue-green deployment means shutting down one system 100% and starting another migrated system at 100%. In our case, this was not feasible and included high risk.
Canary deployment refers to starting a migrated system at X% and shutting down an old system by X%. Such deployment happens continuously whenever needed.
The production deployment challenged us two maintain two things:
Production level indexing on both Elasticsearch clusters.
Querying data from both Elasticsearch clusters without breaking customer experience on the Blinkit app with zero downtime.
Across consumer services, we used a flag to roll out the changes at X% PAN India on the new Elasticsearch cluster whenever we felt confident after going through various stages of testing refactored code.
Overview of our consumer app with a traffic split of 70–30 on both Elasticsearch clusters
Metrics and Performance
Our data indexing pipeline used to take 2 hours to index a complete product catalog. The new refactored indexing pipeline on the new Elasticsearch cluster reduced this time by 1 hour. There was no drop in business revenue and query time also improved in searching and discovering products on the app.
AWS OpenSearch Cloudwatch Metrics
Result of Migration
AWS built-in monitoring support on Cloudwatch.
Logging of key metrics like slow query logs.
AWS supported Kibana for the ES cluster.
Elimination of hacks from product and search service.
Internal optimization in Opensearch caused latency drop across services.
External support of plugins and packages like synonyms as an analyzer.
Next Steps of Improvement
Current problems with our AWS-managed infrastructure is that sometimes we observe abnormal behavior with data node CPU utilization, and there is no proper solution and support from AWS support. This ends up in vertical scaling of the cluster which results in more infrastructure cost for maintaining the AWS-managed cluster. We’re currently working with the AWS team to improve our sharding and replication strategy and how we can query with 5x performance without spiking CPU usage on data nodes and without affecting the writes performance on the cluster.
Special Mentions
Huge thanks to Sachin Jain and Nitesh Jindal for their guidance in planning the roadmap, providing consistent mentorship and giving an opportunity to lead this project. With everyone’s effort, the new Elasticsearch cluster will bring many intelligent business solutions backed by data-driven decisions.
In 1981, Xerox PARC introduced the first Graphical User Interface (GUI), marking a significant shift in computing. Over 43 years, rounded corners have evolved from a design embellishment to an industry standard in both software and hardware.
Setting up our printout delivery store has been extremely satisfying at many levels. At one end is the joy from customers discovering an easy, home-delivered solution for last-minute printouts.
In today’s world, given the pace at which data operates, we need a tool that can help us to generate reports faster and bring out insights within milliseconds.